SECCON 2020 電脳会議でAIセキュリティについて学ぶの巻き
はじめに
2020年12月19日、オンラインにてSECCON 2020 電脳会議に参加しました。
このイベントでは、Room Aと Room Bというように2つのチャンネルに分かれてサイバーセキュリティに関するセッションが複数開かれていました。
イベント自体は10:00~18:45に開かれていたのですが、私用の関係で1つだけ参加することに。
そのセッションが、"実践 Adversarial Examples! ワークショップ"です。
こちらのセッションは機械学習(ディープラーニング)とサイバーセキュリティを掛け合わせたトピックとなっていて、私の好きな組み合わせでもあります。
ワークショップは抽選で落ちてしまったため、参加することができず残念...
しかし、AIセキュリティについての説明やワークショップの様子はオンラインで視聴できました。
セッションの内容は勉強になるものばかりで、AIを開発する人にとっても重要なことだと思うので、記録として記事を書きたいと思います。
実践 Adversarial Examples! ワークショップ について
このワークショップは、大まかなポイントごとに分けると以下のような構成となっていました。
- AIセキュリティについて
- AI開発工程におけるセキュリティ対策
- ワークショップ:Adversarial Examplesの攻撃方法
- ワークショップ:Adversarial Examplesの防御方法
このブログでは、上記の順番に沿ってまとめたいと思います。
なお、参加したワークショップではAIを"機械学習が使用されているシステム全般"と定義していたため、この記事でもAIという単語を同じ定義で使用することにします。
AIセキュリティについて
生体認証、病理診断、商品のレコメンドなどのように、現代ではAIの社会実装が進んでいます。
AIを活用する一方、想定外のデータ入力や高負荷アクセスなどといった、AIに対する攻撃も行われているとのことです。
例えば、顔認証システムにおいて、メイクや眼鏡をかけるといったように、カメラに映る顔が細工されることで顔認証に誤りが生じ、システムや建物への不正侵入を許してしまうということがあります。
また、ドライブ支援システムにおいて、道路標識が細工されることで物体認識に誤りが生じ、事故が発生してしまうというように結果的に人命にかかわる攻撃もあります。
しかし、既存のセキュリティ技術だけでAIを攻撃から守るのは困難です。
そのため、AIを攻撃から守る技術の確立や研究が進んでいます。
AI開発工程におけるセキュリティ対策
そもそも、Webアプリケーションなどに対する従来のセキュリティ対策として、主に以下のものが挙げられます。
- OSのアップデート
- アプリケーションの改修
- セキュリティパッチの適用
上記に対して、AIのセキュリティ対策として挙げられるのが、以下のものです。
- データやモデルの精査
- AI自体の頑健性の向上
このように、従来の方法では後から対策をとることができますが、AIのセキュリティ対策はデータの取得やモデル構築の時点から対策をしなければいけません。
では、具体的にどのようにAIに対してセキュリティ対策を講じるべきでしょうか?
AI開発工程におけるセキュリティのポイントの紹介があったので、箇条書きでまとめます。
- 学習データの入手元は信頼できるか
- 外部からデータを取得するとき、不正なデータが含まれていないか
- データのラベル付けは正しいか
- 事前学習モデルの入手元は信頼できるか
- 事前学習モデルは細工されていないか
- フレームワーク/ライブラリを正しく使用しているか
- 最新バージョンのフレームワーク/ライブラリを使用しているか
- 入力データは細工されていないか
- モデルは不正な入力データに対して頑健か
- 必要以上の情報を応答していないか
これらのポイントは、モデルを構築するときに当たり前のことでは?と思う方が多いかもしれません。
しかし、このような対策をしっかり取らないと、MLフレームワークの機能を悪用してシステムへの侵入・機微情報の窃盗や、悪意のあるクエリアクセスによる誤認識の誘発などを許してしまいます。
また、AIのモデル構築において気を付けるべきこととして過学習を防ぐということがありますが、こちらもセキュリティ対策としても重要なことです。
一般的に、過学習しているモデルは訓練データに適合しすぎているため、テストデータに対して精度が低くなります。
この仕組みを利用することによって、訓練データが特定できてしまい、情報漏洩の発生や次の攻撃方法のヒントになってしまうとのことです。
このような攻撃を受けないために、AIのセキュリティ対策がとても重要なことが分かります。
ワークショップ:Adversarial Examplesの攻撃方法
このセッションのタイトルにある、Adversarial Examples(敵対的サンプル)とは、AIの誤認識を誘発させる手法のことです。
例えば、画像分類を行うAIに対して、わざとノイズを足した画像を与えて分類を間違えさせるという手法があります。
以下の画像は、Adversarial Exampleに関する有名な論文*1から持ってきたものです。
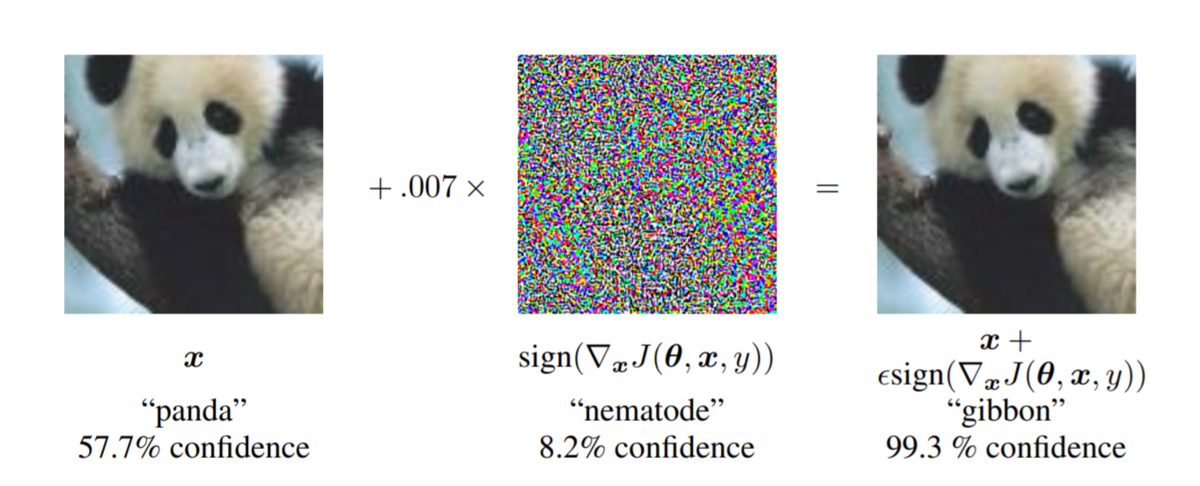
通常のパンダの画像にノイズを足したものを入力としてモデルに与えると、パンダではなくテナガザルとして分類してしまいます。
これを悪用することによって、AIが誤認識して重大なセキュリティ事故を引き起こすことになってしまいます。
今回のワークショップでは、AIに対する攻撃手法と防御手法をハンズオンで実践して、AIセキュリティの重要性を理解するということが目的であり、運営側が用意したGoogle Colabを使用して学ぶという流れです。
具体的には、Tensorflow、Keras、Adversarial Robustness Toolbox(ART)と呼ばれるMLセキュリティ用のPythonライブラリを使用して攻撃用の画像を生成し、運営が用意した脆弱性のあるAIに生成した画像を与えると、どのように分類されるのかを検証しました。
ARTには様々な関数が用意されているのですが、私自身まだライブラリを使用していないため、今回の記事では書かないことにします。
ワークショップ:Adversarial Examplesの防御方法
ワークショップの後半は、Adversarial Examplesの攻撃に対して、どのような対策があるのかをGoogle Colabを使用して学びました。
今回はフィルタ処理を取り込んで、不正なデータが入力されても誤認識しないようにすることを検証。
具体的なフィルタ処理の方法ですが、モデルが画像分類を行う前に入力データの圧縮やカラービット深度の削減による情報量の削減を行うことによって、元の入力データにノイズが足されても誤認識を防ぐというものでした。
ワークショップで入門編ということもあり、処理の効果はあったものの完全に防げるものではありませんでしたが、ゴリゴリに実装することによって誤認識をする確率がかなり減らすことができるという印象でした。
防御方法についても、まだライブラリを使用していないため、今回の記事では書きません。
おわりに
AIの精度を上げるためにも、データの精査やどのデータに対しても汎化性能を高めることは普通ですが、立派なセキュリティ対策にもなることが分かりました。
このセッションを視聴してみて、自分でもコードを書いて検証してみたいというのが一番の感想です笑
ということで、実際のコードの書き方や検証は自分なりにまとめて記事を書く予定なのでお楽しみに。