Makeover Mondayのサイトでパブリッシュされているデータをartisticallyに可視化してみた
業務でTableauを使用してデータをグラフやクロス集計表として可視化をしている、データサイエンティスト兼データエンジニア兼BIエンジニアです。
今回は、Tableauで単にデータを可視化するだけでなく、ダッシュボードのデザインも考えるという少しオシャレなことに挑戦してみました。
もともと、デザインを考えるのも好きなので、Tableauのダッシュボードもアートっぽいものにしてみたいなと思っていたのですが、可視化したいデータがなかったり、見つけてもデータの質がイマイチということがありました。
そんなときに、Makeover Mondayというプロジェクトを知りました。
Makeover Mondayとは?
Makeover Mondayとは、週次でデータ可視化の特訓を行うという、無料で参加できるプロジェクトです。
可視化するときのツールはTableauに限らず、PythonやRでもなんでもOKです。
2016年から行われており、今年は1月4日から9月26日まで毎週日曜日に新しいデータがパブリッシュされ、月曜日にデータを可視化、火曜日~土曜日は可視化したものをシェアしたりフィードバックセッションに参加するなどがあるようです。
私はこのプロジェクトの存在をつい最近知ったので、late subみたいな感じでこの土日に自由に作成していました。
今のところ毎年あるようなので、2022年はリアルタイムで参加できるようにしたいです。
今回の作成物
Makeover Mondayのデータセットを一通り見て、面白そうなデータを3つピックアップしてTableauで可視化しました。
Tableauのダッシュボードは、パソコンでの閲覧を推奨します。
Dark Web Price Index in 2021
ダークウェブにある、商品/サービスの平均価格を可視化しました。
商品はカテゴリごとに分類できるので、カテゴリごとの合計価格をワードクラウドで可視化し、それをフィルターとしても使用できるように下の棒グラフと連動させました。
作成したダッシュボードのスクショです。
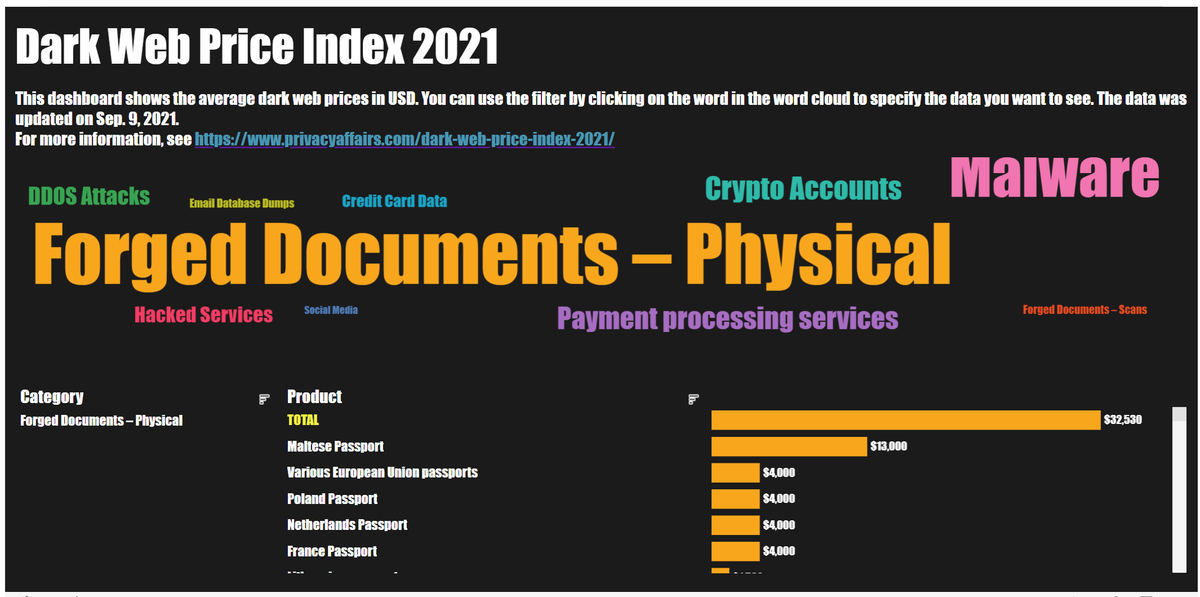
そして、以下がTableau Publicにアップロードしたダッシュボードのリンクです。
実際に触ってみたい方は、こちらからどうぞ。
https://public.tableau.com/app/profile/maho.uchida/viz/DarkWebPriceIndex2021_16366509051540/DarkWebPriceIndex2021
Top 20 Largest Solar Power Plants
世界で最も大きい太陽光発電所のトップ20のデータを可視化したものです。
ダッシュボードをパッと見ても、太陽光発電所に関するデータだと分かるように、ダッシュボードをフライヤー風に作成してみました。
作成したダッシュボードのスクショです。

そして、以下がTableau Publicにアップロードしたダッシュボードのリンクです。
黄色のマークにマウスオーバーすると、スクショのようにデータが見れるようになっています。
https://public.tableau.com/app/profile/maho.uchida/viz/Top20LargestSolarPowerPlants/1_1
The Average Cost of 1GB Mobile Data in USD by Country
国ごとの1GBのモバイルデータの価格を可視化するということで、真っ先にスマホからデータを見ているような構造が浮かんできて、作成しました。
もともと、国名と価格と価格のランク(安い方が1位)のデータのみだったので、リージョンのデータを持ってきてフィルターをかけられるようにしました。
作成したダッシュボードのスクショです。
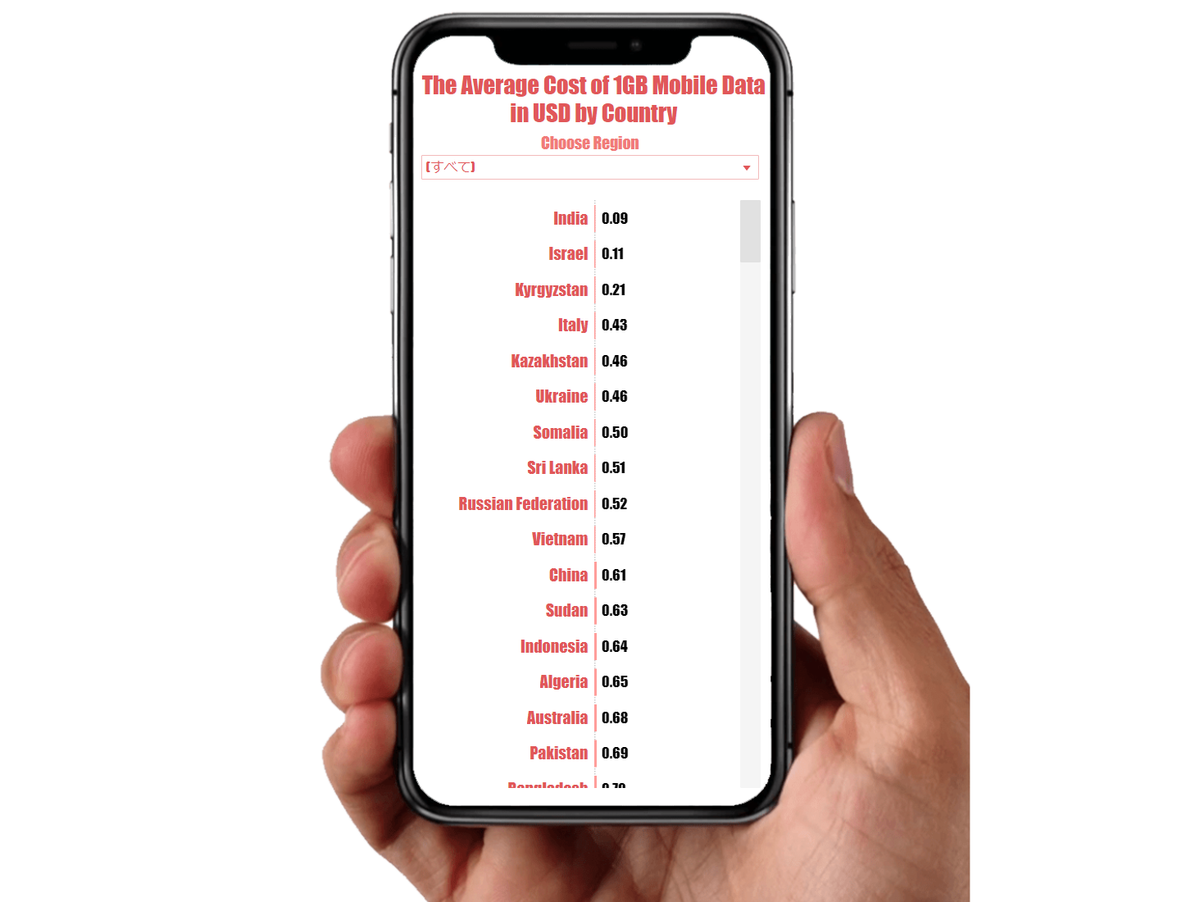
そして、以下がTableau Publicにアップロードしたダッシュボードのリンクです。
実際に触ってみたい方は、こちらからどうぞ。
https://public.tableau.com/app/profile/maho.uchida/viz/TheAverageCostof1GBMobileDatainUSDbyCountry/1_1
SECCON Beginners Live 2021 に参加しました
2021年10月17日、オンラインにてSECCON Beginners Live 2021に参加しました。
今回はCTF初心者向けのセッションとして、過去に出題された問題の解説を交えながらどのようにFlagを取得するのかという解説が盛りだくさんでした。
最近は常設CTFにも参加できていないので、セッションを聴いているうちに参加したくなりました笑
(ちなみに、この記事を書いている今はatma Cupというデータサイエンスコンペに参加しているので、CTFをやるのは来週以降になりそうです)
セッションごとに簡単なメモを取ったので、備忘録としてまとめます。
- イントロダクション
- Magicで学ぶWebセキュリティ
- Flag🚩のきもち ビギナー向けFlag獲得への足掛かり
- SECCON Beginners CTF2021のCryptoを解いてみよう
- 誘導を読み取って1ステップ上の問題を解けるようになろう
- Beginners Beginners ROP
イントロダクション
イントロダクションでは、以下の5点についてお話がありました。
(CTFをご存知の方は、基本的な内容なので飛ばして問題ないです)
- SECCON Beginners について
- CTFとは何か
- CTFで出題されるジャンル
- CTFの勉強方法
- CTFと法律・倫理
過去の記事で書いたかと思いますが、CTFとは、Capture The Flagの略称で、情報セキュリティ・サイバーセキュリティに関するスキルを競うコンテストです。
具体的には、Flagと呼ばれる文字列を、脆弱なアプリケーションに攻撃したり暗号の解読などをして取得し、点数を稼いでいくというものになっています。
CTFで出題されるジャンルは5つあり、問題の難易度によって1問あたりの点数が変わります。
- Web:Webアプリケーションの脆弱性を突く問題
- Crypto (Cryptography):暗号の解読を行う問題
- Reversing:リバースエンジニアリングや、バイナリ解析を行う問題
- Pwn(Pwnable):プログラムの脆弱性を突く問題
- Misc (Miscellaneous):上記のジャンルに含まれない問題(NetworkやForensicsなどの問題)
CTFでは、どの問題でもコンピュータサイエンスの知識が必須です。
勉強法としては自分が興味があるジャンルに絞って、その分野の基礎知識を学ぶことが重要とのことです。
最後の法律・倫理については、許可なく実際のサーバやアプリケーションを攻撃すると罪に問われるのでやめましょう、というお話です。
Magicで学ぶWebセキュリティ
過去に出題された、WebのMagicと呼ばれる問題をもとに、複数の攻撃手法を組み合わせてFlagを取得する方法や、攻撃する際のマジックリンクの活用方法の紹介してくださいました。
ちなみにマジックリンクとは、共有されたURLにアクセスするだけでログインできるという、パスワード入力が不要な認証方法です。
opluswork.com
問題を解くコツは以下の通りで、今回の場合はアプリケーションの脆弱性とマジックリンクの特性を活かした攻撃をするとFlagが取得できるというものでした。
- Webアプリケーションの仕組みを理解し、コードを読んで挙動確認する
- Flagのある場所から、攻撃手法を決める
- 攻撃できる場所(Webページ)や、Webアプリケーションの機能を把握して、具体的な攻撃シナリオを立てる
- ブラウザのセキュリティ機構の設定を把握する
Flag🚩のきもち ビギナー向けFlag獲得への足掛かり
CTF初心者~中級者向けの発表で、どのようにFlagの場所から解法を見つけるのか、という流れを紹介していただきました。
まず、登壇者が思う、Flagを取得するために重要なことは以下の通りとのことです。
CTFでは限られた時間内でどのくらい得点を得られるかが勝負です。
そのため、CTF中級者以上は、Flagの場所から脆弱性を絞って攻撃をしたり、Flagの場所から逆算して攻撃するということを行っています。
Flagの場所は問題のジャンルによって異なりますが、ジャンルを名前から大体の目星は簡単につきます。
例えば、Webフロントやソースコードを見て、クローラにFlagがあると仮定した場合、XSSなどクローラを対象とした脆弱性に絞ります。
他にも、ソースコードからデータベースを操作しそうな実装があるため、データベースにFlagがありそうだと仮定した場合、SQLiなどデータベースを対象とした脆弱性に絞ります。
Flagの場所から逆算する場合、例えばFlagの場所的にJavaScriptを実行すれば取得できるとします。
そのJavaScriptを実行させるにはどのような攻撃をすればよいのか、といったように考るということです。
問題をこなしていくと、Flagの場所から逆算しなくても解法が分かるようになります。
そのため、Flagの場所というのは重要な手掛かりになるということです。
SECCON Beginners CTF2021のCryptoを解いてみよう
このセッションでは、過去に出題された、以下の2つの問題の解説が行われました。
- simple_RSA
- Logical_SEESAW
1つ目のsimple_RSAでは、小さい公開鍵 e でRSA暗号の復号を行う攻撃手法(Low Public Exponent Attack)を使います。
運営が用意したプログラムから情報を得て、復号化を行うコードを書いて実行させるとFlagが取得できるという解法でした。
2つ目のLogical_SEESAWでは、与えられたソースコードから論理演算を導き、復号化するコードを書くというものです。
昨今のCryptoの問題では、コードが書けるのが前提で出題される傾向があるとのことで、まさに上記の2つの問題はコードを書かないとFlagを取得することができないようになっています。
誘導を読み取って1ステップ上の問題を解けるようになろう
CTFに取り組んでいると、どこにFlagがあるか分からないこともあります。
そのような場合、"誘導" (= 解答者をFlag取得に導く情報)を読み取ってFlagの場所を推定することができます。
では、その誘導をどこから読み取るのかということですが、主に3つの方法があります。
- ジャンル・問題名・問題文から得る
- 配布ファイルの表層から得る
- 配布ファイルを解析して得る
ジャンル・問題名・問題文から得るというのはそのままの意味であり、例えばジャンルからどのような攻撃手法を用いるかを絞ることができます。
また、問題名・問題文には、具体的な解法のヒントが隠されています。
配布ファイルの表層から得るというのは、コマンドを実行してファイルのメタ情報や種類から情報を得るということです。
問題のジャンルによってはコマンドを実行するだけでなく、ツールに読み込ませる必要なときもあります。
最後の配布ファイルを解析して得るということに関しては、以下の2種類の解析方法を使い分けて情報を得るということです。
- 静的解析(ファイルを実行せずに解析)
- 動的解析(ファイルを実行して解析)
ファイルを実行させないと分からないのではと思う方もいるかもしれませんが、例えばコードが書かれているファイルの中にコメントアウトされている箇所があるとします。
その場合、意図的にコメントアウトされている可能性が高いので、不要なコードに見えても必要だから書かれているという場合が多いです。
誘導を読み取るのは、どのように攻撃するのかを決める1つのテクニックであり、ミスリードや勘違いをするときもあるので注意が必要とのことです。
Beginners Beginners ROP
このセッションでは、Beginners ROPという過去の問題をもとに、Pwnの解き方を解説してくださいました。
まず、ROPとはReturn Oriented Programmingの略で、攻撃者がバッファオーバーフローなどといったプログラムのバグを利用してコールスタックを操作するという攻撃手法です。
ROPを知らなくても、いかに新しい攻撃手法を競技中に理解して実践するということが重要です。
Tableauで可視化していた、埼玉県のCOVID-19の陽性確認者数のダッシュボードの運用を停止します
はじめに
WTH, 埼玉県のコロナ陽性確認者数のデータを使用して、Tableauのダッシュボードを更新し続けてたのに、県のサイトからcsvの元データがダウンロードできなくなっちゃった!😇 多分、陽性者確認者数が多くなりすぎて集計しきれないのか?
— махо учида(Mаho) (@a7xChe) August 14, 2021
という訳で、ダッシュボードの運用を停止します。
ことの経緯をもう少し詳しく説明しますと、以下の通りです。
今までは埼玉県のサイトからcsv形式のファイルをダウンロードしていて、各陽性確認者ごとに年代や市町村、性別のデータが含まれていました。
しかし、8月上旬のとある日から各陽性確認者ごとの情報ではなく、市町村ごとの陽性確認者数や人口10万人あたりの新規陽性確認者数といった、サマリのデータがサイトに表示されるようになりました。
ちなみに、以下がそのサイトです。
まさか、データが取れなくなることが原因で運用停止するとは思いませんでしたが...
データの更新はできませんが、ダッシュボード自体は削除せずにとっておく予定です。
今後、別のデータを使用したダッシュボードを作成するのか?
はい、作成する予定です。
Tableauで色々試してみたいことがあるので、何かしらは作ります。
とりあえず、自分の住んでいる市のサイトでコロナウイルス陽性確認者ごとの年代・性別・症状などの情報も開示されているデータを見つけたので、そのデータを使用しようかなと思っています。
(まぁ、住んでいる市くらいは別に公表しても問題ないかなと... 何かあれば武術で応戦します)
確かデータがPDF形式なので、Pythonでの前処理がちょっと厄介そうですが、できなくはないのでやってみます。
ただ、あまりにも対象地域がピンポイント過ぎて、そもそもダッシュボードの需要がなさそうな気もしているので、データを変える可能性もありますが、完成したらまたブログで記事を書きます。
Tableauで埼玉県におけるCOVID-19の陽性確認者のデータを可視化をしてみた(6/6/2021 8:50 pm 時点 公表データ)
はじめに
どうも、最近の主な業務内容がデータマート構築&Tableau職人のデータサイエンティストです。
1年以上前にTableauで埼玉県のCOVID-19 陽性確認者数を可視化しましたが、2020年9月13日以来 一度も更新していなかったので久しぶりに更新しました。
過去に書いたブログの記事は↓です。
Tableau PublicのプロフィールにLinkedInのリンクも載せているのですが、嬉しいことにLinkedIn経由で可視化してくれてありがとう!というメッセージを一度だけですが受け取りました。
ダッシュボードをどのように使用したのかはメッセージには書いていなかったのですが、埼玉県の公式ホームページからデータを持ってきているので、データ自体は信用はできると思います。
そんなこともあって、ふと思い出したかのように久しぶりにダッシュボードを更新しました。
需要があるかは不明ですが、明日からはちゃんと更新頻度を上げようと思います。
作成したダッシュボード
前置きはこれくらいにしておいて、作成したダッシュボードは以下のリンクから見ることができます。
今回作成したダッシュボードは、"COVID-19 in Saitama" というタイトルのものです。
※ パソコンでの閲覧を推奨
以前のダッシュボードから少し変更を加えたので、少し見やすくなったかと思います。
といっても、過去のものを上書きして更新したので、以前のは見れないですが...笑
Micro Hardening v2 に参加しました
2021年5月4日、オンラインにてMicro Hardening v2に参加しました。
(今更感がありますが、てっきり公開したと思ったら下書きを更新していただけで公開していませんでした汗)
とある知り合いから、セキュリティに関する面白そうなイベントがあるよ!とわざわざ私に連絡をしてくださり、connpassにて参加登録をしました。(連絡してくださり、本当にありがとうございました <(_ _)> めちゃめちゃ楽しかったです!)
イベントの概要などは後述しますが、イベントを通じてセキュリティに関してより詳しくなることができました。
Micro Hardening v2 とは
Micro Hardeningとは、主催者が用意したECサイトの管理者としてサイバー攻撃の対処をするというプロジェクトです。
(v2がついているのは、前回のバージョン(= v1)から競技の環境の更新を行ったり、評価方法を少し変更してアップデートしたためのようです。)
このプロジェクトは、ゲーム感覚でサイバー攻撃に対処する能力を身につけるということがコンセプトであり、チームを組んでスコア(= ECサイトの売上)を稼いで競い合います。
競技の流れですが、競技が開始すると主催者が用意したクローラが動き出してECサイトで買い物を開始しますが、同時にサイトへの攻撃も始まります。
そのため、スコアを稼ぐために参加者はサイトを攻撃されないように設定を変更、または攻撃をされた後に適切にサイトを回復させる必要があります。
今回は、事前準備30分+競技45分を1セットとして計3回行いましたが、いずれのセットもクローラは全く同じ動きをするため、1セット目の反省を2セット目で活かすといったように繰り返し演習を行って対処方法を学ぶという流れでした。
プロジェクトの詳細は、今後参加する方へのネタバレになってしまうということであまり書けませんが、クローラの攻撃内容と対処方法は実務でも経験する可能性があるので、セキュリティに興味があるエンジニアにおすすめです。
また、今回参加したMicro Hardening v2はコミュニティ版であり、有償の企業向けのトレーニング版もあるとのことです。
チーム編成
connpassでの登録時は1人で参加しようと思っていたのですが、説明文をよく見るとチーム戦であることに後から気が付きました。
チームは知り合い同士で組むことも可能ですが、チームのメンバーの登録は主催者が用意したスプレッドシートに記入するというものでした。
私は勉強会が始まる15分前に、人数に空きがあるチームに名前を記入しました。
今回は、HUIT(北海道大学IT研究会)の方々のチームに入れて頂きました。
私が急に加入したのにも関わらず、一緒にプロジェクトを進めてくださってありがとうございました!
全セット終了後
全てのセットが終了したあとは、それぞれのチームがどのようにECサイトの設定を変更したのか、攻撃に対してどのように対処をしたのかを共有する時間がありました。
参加したチームの中には経験者で構成されたチームがありましたが、そのチームの対処法がスマートかつ的確な対処をしていて非常に勉強になりました。
本業がデータサイエンティストなので、このような機会でないと本格的な体験が今のところできないので、次回以降もぜひ参加したいと思いました。
後日談
HUITの方々とMicro Hardening v2の振り返り会を行いました。
大学時代はComputer Science Major の友だちと外部のコンペやプロジェクトに参加することがなかったので、私もちょっとした学生気分で参加させていただきました笑
HUITの皆さん、また機会があればよろしくお願いします!
AI Quest 2020 に参加しました
2020年10月から参加していたAI Quest 2020が、2021年2月21日に修了しました。
約5ヶ月間、仕事終わりや土日に課題をこなしてきたため、社会人の私にとって少しハードでしたがとても良い経験になりました。
プログラムの具体的な内容は、今後開催されるAI Questのネタバレになってしまうということで詳細は書けませんが、プログラムの概要とともに参加した目的と感想を記事として簡単に残したいと思います。
AI Questとは
AI Questとは、経済産業省が主体となって行っている、AI人材を育成するためのプロジェクト型学習プログラムです。
今回私が参加したAI Quest 2020では、1つのテーマに対して以下の一連の流れを1つのタームとし、2タームありました。
- AIを導入するためのビジネス課題の洗い出し
- PoCの要件定義
- モデル構築・評価
- 経営者に向けた実装運用計画のプレゼン資料作成
参加者によっては、1ターム + 企業とのAI導入協働プログラムに参加することができました。
(私は普段の仕事が忙しかったため、協働プログラムの参加は諦めてしまいました...)
協働プログラムに参加した方々の成果発表によると、実際に企業が抱えている課題を解決するために企業の方と週に1度のミーティングなどをしながらモデルの実装・評価まで進めていくというものだそうで、時間があれば参加したかったなと思っています。
参加した目的
現在、データサイエンティストとして働いていますが、なぜAI Questに参加したのかを書き記します。
モデル構築のスキルは、KaggleやSIGNATEといったコンペティションに参加すれば経験を積むことができます。
しかし、企業の課題を洗い出してAIを導入するという、コンサルタントの仕事の経験を積むことができる学習プログラムはなかなか無いと思いました。
また、2タームあったので、1ターム目で勉強したことをすぐに2ターム目に活かすことができるという内容だったので、学んだものをすぐにアウトプットできる環境が整っていると感じました。
そのため、AI Questに参加することを即決しました。
AI Questに参加した感想
結論から言うと、私にとってAI Questの参加は有意義でした。
AI Questは、他の受講者と切磋琢磨しながら課題をこなしていくため、AI Quest用のSlackで情報共有・コミュニケーションをとりながら課題を進めていきます。
また、週末は運営側が用意したRemoで参加者同士が気軽に交流することもできます。
そのため、私が参加した今回のAI Questでは、課題をこなしていく過程での助け合いだけでなく、様々な業種・業界×AIについての話題の提供や、その業種・業界ならではの知識の共有が盛んに行われていました。
個人的には、現役コンサルタントの方々が丁寧に教えてくださった意思決定のためのプレゼン資料の作成方法がとても参考になり、今後の実務でも活かしていく予定です。
AI Questが終了した後も、コミュニティを存続させるためにSlackでの運用は続けるとのことで、この記事を執筆している現在でもAIや機械学習・深層学習に関する情報共有は積極的に行われています。
他にも、ある参加者が中心となって、AI Questの課題を模してチーム戦を行うという独自のコンペも開いています。
私が参加したAI Quest 2020は、本来の目的であるプログラムを通してのスキルアップだけでなく、個々の長期的なキャリアアップを目指すための学び合いの場でもあると感じています。
SECCON 2020 電脳会議でAIセキュリティについて学ぶの巻き
はじめに
2020年12月19日、オンラインにてSECCON 2020 電脳会議に参加しました。
このイベントでは、Room Aと Room Bというように2つのチャンネルに分かれてサイバーセキュリティに関するセッションが複数開かれていました。
イベント自体は10:00~18:45に開かれていたのですが、私用の関係で1つだけ参加することに。
そのセッションが、"実践 Adversarial Examples! ワークショップ"です。
こちらのセッションは機械学習(ディープラーニング)とサイバーセキュリティを掛け合わせたトピックとなっていて、私の好きな組み合わせでもあります。
ワークショップは抽選で落ちてしまったため、参加することができず残念...
しかし、AIセキュリティについての説明やワークショップの様子はオンラインで視聴できました。
セッションの内容は勉強になるものばかりで、AIを開発する人にとっても重要なことだと思うので、記録として記事を書きたいと思います。
実践 Adversarial Examples! ワークショップ について
このワークショップは、大まかなポイントごとに分けると以下のような構成となっていました。
- AIセキュリティについて
- AI開発工程におけるセキュリティ対策
- ワークショップ:Adversarial Examplesの攻撃方法
- ワークショップ:Adversarial Examplesの防御方法
このブログでは、上記の順番に沿ってまとめたいと思います。
なお、参加したワークショップではAIを"機械学習が使用されているシステム全般"と定義していたため、この記事でもAIという単語を同じ定義で使用することにします。
AIセキュリティについて
生体認証、病理診断、商品のレコメンドなどのように、現代ではAIの社会実装が進んでいます。
AIを活用する一方、想定外のデータ入力や高負荷アクセスなどといった、AIに対する攻撃も行われているとのことです。
例えば、顔認証システムにおいて、メイクや眼鏡をかけるといったように、カメラに映る顔が細工されることで顔認証に誤りが生じ、システムや建物への不正侵入を許してしまうということがあります。
また、ドライブ支援システムにおいて、道路標識が細工されることで物体認識に誤りが生じ、事故が発生してしまうというように結果的に人命にかかわる攻撃もあります。
しかし、既存のセキュリティ技術だけでAIを攻撃から守るのは困難です。
そのため、AIを攻撃から守る技術の確立や研究が進んでいます。
AI開発工程におけるセキュリティ対策
そもそも、Webアプリケーションなどに対する従来のセキュリティ対策として、主に以下のものが挙げられます。
- OSのアップデート
- アプリケーションの改修
- セキュリティパッチの適用
上記に対して、AIのセキュリティ対策として挙げられるのが、以下のものです。
- データやモデルの精査
- AI自体の頑健性の向上
このように、従来の方法では後から対策をとることができますが、AIのセキュリティ対策はデータの取得やモデル構築の時点から対策をしなければいけません。
では、具体的にどのようにAIに対してセキュリティ対策を講じるべきでしょうか?
AI開発工程におけるセキュリティのポイントの紹介があったので、箇条書きでまとめます。
- 学習データの入手元は信頼できるか
- 外部からデータを取得するとき、不正なデータが含まれていないか
- データのラベル付けは正しいか
- 事前学習モデルの入手元は信頼できるか
- 事前学習モデルは細工されていないか
- フレームワーク/ライブラリを正しく使用しているか
- 最新バージョンのフレームワーク/ライブラリを使用しているか
- 入力データは細工されていないか
- モデルは不正な入力データに対して頑健か
- 必要以上の情報を応答していないか
これらのポイントは、モデルを構築するときに当たり前のことでは?と思う方が多いかもしれません。
しかし、このような対策をしっかり取らないと、MLフレームワークの機能を悪用してシステムへの侵入・機微情報の窃盗や、悪意のあるクエリアクセスによる誤認識の誘発などを許してしまいます。
また、AIのモデル構築において気を付けるべきこととして過学習を防ぐということがありますが、こちらもセキュリティ対策としても重要なことです。
一般的に、過学習しているモデルは訓練データに適合しすぎているため、テストデータに対して精度が低くなります。
この仕組みを利用することによって、訓練データが特定できてしまい、情報漏洩の発生や次の攻撃方法のヒントになってしまうとのことです。
このような攻撃を受けないために、AIのセキュリティ対策がとても重要なことが分かります。
ワークショップ:Adversarial Examplesの攻撃方法
このセッションのタイトルにある、Adversarial Examples(敵対的サンプル)とは、AIの誤認識を誘発させる手法のことです。
例えば、画像分類を行うAIに対して、わざとノイズを足した画像を与えて分類を間違えさせるという手法があります。
以下の画像は、Adversarial Exampleに関する有名な論文*1から持ってきたものです。
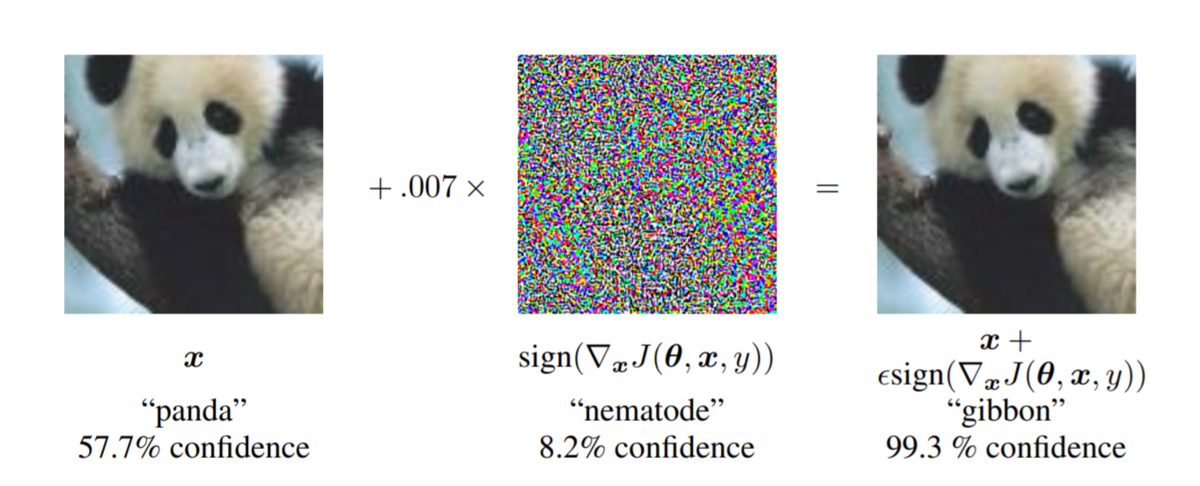
通常のパンダの画像にノイズを足したものを入力としてモデルに与えると、パンダではなくテナガザルとして分類してしまいます。
これを悪用することによって、AIが誤認識して重大なセキュリティ事故を引き起こすことになってしまいます。
今回のワークショップでは、AIに対する攻撃手法と防御手法をハンズオンで実践して、AIセキュリティの重要性を理解するということが目的であり、運営側が用意したGoogle Colabを使用して学ぶという流れです。
具体的には、Tensorflow、Keras、Adversarial Robustness Toolbox(ART)と呼ばれるMLセキュリティ用のPythonライブラリを使用して攻撃用の画像を生成し、運営が用意した脆弱性のあるAIに生成した画像を与えると、どのように分類されるのかを検証しました。
ARTには様々な関数が用意されているのですが、私自身まだライブラリを使用していないため、今回の記事では書かないことにします。
ワークショップ:Adversarial Examplesの防御方法
ワークショップの後半は、Adversarial Examplesの攻撃に対して、どのような対策があるのかをGoogle Colabを使用して学びました。
今回はフィルタ処理を取り込んで、不正なデータが入力されても誤認識しないようにすることを検証。
具体的なフィルタ処理の方法ですが、モデルが画像分類を行う前に入力データの圧縮やカラービット深度の削減による情報量の削減を行うことによって、元の入力データにノイズが足されても誤認識を防ぐというものでした。
ワークショップで入門編ということもあり、処理の効果はあったものの完全に防げるものではありませんでしたが、ゴリゴリに実装することによって誤認識をする確率がかなり減らすことができるという印象でした。
防御方法についても、まだライブラリを使用していないため、今回の記事では書きません。
おわりに
AIの精度を上げるためにも、データの精査やどのデータに対しても汎化性能を高めることは普通ですが、立派なセキュリティ対策にもなることが分かりました。
このセッションを視聴してみて、自分でもコードを書いて検証してみたいというのが一番の感想です笑
ということで、実際のコードの書き方や検証は自分なりにまとめて記事を書く予定なのでお楽しみに。